


Introduction
BNB Chain is one of the most burst-heavy EVM networks in production, placing exceptional demands on BNB RPC infrastructure.
Traffic patterns are highly volatile and often unpredictable, driven by:
memecoin launches and trading activity
leveraged and high-frequency trading
prediction markets
arbitrage bots and MEV flows
In these moments, BNB RPC infrastructure becomes the critical scaling layer, not because the chain slows down, but because applications depend on RPC availability to stay responsive.
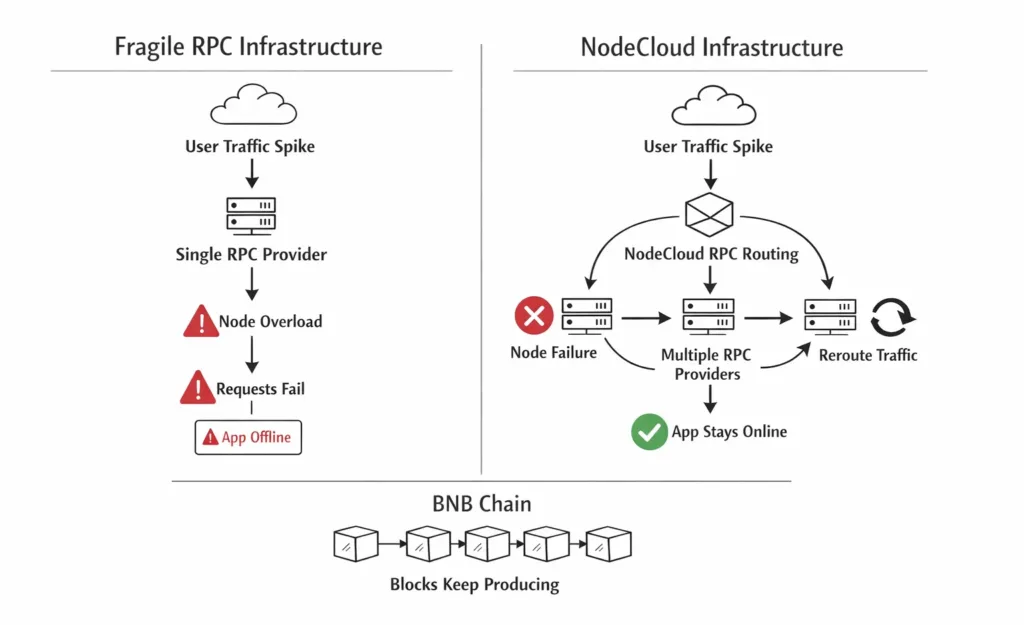
Blocks continue to be produced, but applications can degrade or appear offline when RPC layers cannot absorb traffic spikes. For teams building on BNB Chain, execution reliability depends directly on how RPC infrastructure is designed and operated.
If you’re looking for a broader architectural overview of how RPC fits into dApp systems, the BNB Chain RPC Infrastructure Guide: How to Connect, Scale, and Choose the Right Setup provides additional context on available approaches.
NodeCloud: Designed for Uptime and Resilience
NodeCloud was built with a single non-negotiable goal: stay available under real-world conditions, especially during extreme bursts typical for BNB RPC infrastructure workloads.
Rather than optimising for a single traffic origin, NodeCloud is engineered as a resilience-first RPC layer, capable of absorbing sudden demand and routing around failures in real time.
Core design principles
Decentralised provider set
Traffic is distributed across a network of independent node operators. If one provider degrades, requests are automatically routed elsewhere.
Client diversity by default
Multiple execution clients run in parallel, reducing the blast radius of client-specific bugs or sync issues.
Real-time health-aware routing
Routing decisions continuously account for latency, error rates, and node health. Feedback loops update routing behaviour every few seconds to adapt to changing traffic patterns.
Built for stress, not averages
NodeCloud is designed to handle worst-case scenarios while remaining efficient during normal operation.
NodeCloud is part of dRPC’s broader infrastructure stack and is accessible through curated endpoint listings on the dRPC BNB Chain RPC page, alongside managed routing and observability.
Real-World Stress Scenarios on BNB Chain
BNB Chain regularly experiences periods of extreme demand where BNB RPC infrastructure is placed under sustained stress.
During these events:
Request volumes can spike by orders of magnitude
Latency sensitivity increases dramatically
Partial failures at the RPC layer can cascade into user-facing outages
In many cases, the blockchain itself continues operating normally. Blocks are produced and finalized, but applications suffer due to overloaded or fragile RPC setups.
These scenarios highlight a core truth:
RPC disruptions are rarely caused by the chain itself.
They are caused by infrastructure designs that cannot absorb real-world traffic patterns.
Why This Matters for BNB Chain Applications
BNB Chain applications are particularly sensitive to RPC instability because every user-facing interaction depends on BNB RPC infrastructure:
Trades may fail or stall
Wallets can display stale balances
Bots miss execution windows
dApps appear “down” even while the network remains live
For teams evaluating request models and performance tradeoffs under high load, this breakdown of RPC vs REST for blockchain applications explains why RPC infrastructure behaves differently during traffic spikes.
In most incidents, BNB Chain continues producing blocks. The point of failure is the RPC access layer.
For developers and infrastructure teams, this makes RPC architecture a first-class design decision rather than an operational afterthought.
For developers evaluating different setups, the BNB Chain RPC Infrastructure Guide: How to Connect, Scale, and Choose the Right Setup provides a deeper breakdown of architectural tradeoffs.
Distributed RPC as an Architectural Pattern
Modern RPC infrastructure increasingly treats RPC not as a single service, but as a distributed system.
Distributed RPC architectures are designed to:
Route around partial failures automatically
Reduce dependency on any single node, client, or provider
Maintain availability even when individual components degrade
This approach aligns with recommendations found in the official BNB Chain developer documentation, where redundancy and infrastructure diversity are encouraged as best practices.
NodeCloud follows this distributed model, focusing on availability, resilience, and graceful degradation under stress.
NodeCore: Complementing NodeCloud
While NodeCloud focuses on global availability for BNB RPC infrastructure, NodeCore enables teams to operate custom, self-managed RPC gateways within their own environments.
NodeCore is suited for teams that require:
Specific latency targets
Cost optimisation
Compliance or deployment constraints
Fine-grained routing control
Together, NodeCloud and NodeCore form a layered approach:
NodeCloud → maximum uptime, traffic absorption, and resilience
NodeCore → fine-grained control and optimisation for specialised workloads
This combination allows teams to adapt their RPC architecture as requirements evolve, without committing to a single rigid model.
Key Takeaway
BNB Chain applications do not fail because the chain stops.
They fail when BNB RPC infrastructure is not designed to handle real-world conditions.
Reliable RPC availability requires:
Distributed providers
Health-aware routing
Client diversity
Infrastructure built for burst traffic
NodeCloud exists to help applications stay online when traffic surges, while NodeCore enables teams to tailor RPC infrastructure to their own operational needs.
That difference between a simple RPC endpoint and resilient infrastructure is what determines whether applications remain reliable under pressure.
FAQs
What is RPC infrastructure on BNB Chain?
RPC infrastructure is the communication layer that allows wallets, dApps, and bots to read blockchain data and submit transactions to BNB Chain via JSON-RPC endpoints.
Why is availability so important for BNB RPC infrastructure?
Because BNB Chain traffic is highly bursty, RPC systems must handle sudden spikes without degrading application performance.
Does distributed RPC mean decentralised?
Distributed RPC reduces single points of failure by routing across multiple providers and nodes, even if a single control plane remains.
How does NodeCloud improve availability?
NodeCloud uses multiple providers, client diversity, and real-time health-aware routing to maintain uptime during stress events.
When should teams consider NodeCore?
NodeCore is suitable when teams need custom routing, compliance control, or on-prem infrastructure tailored to their architecture.
Can NodeCloud and NodeCore be used together?
Yes. Many teams combine managed distributed RPC with self-managed gateways for maximum flexibility and resilience.
